 Outil Union
Outil Union
 Outil Union
Outil Union
Exigences relatives au rôle d'utilisateur
Rôle d'utilisateur* | Accès aux outils/fonctionnalités |
|---|---|
Utilisateur complet | ✓ |
Utilisateur de base | ✓ |
*S'applique aux clients Alteryx OneÉditions Professional et Enterprise sur les versions 2025.1 et ultérieures de Designer.
Utilisez l'outil Union pour combiner 2 jeux de données ou plus, en se basant sur les noms ou les positions des colonnes. Dans la sortie, chaque colonne contient les lignes de chaque entrée. Vous pouvez configurer la façon dont les colonnes s'empilent ou se rejoignent dans la sortie.
Consultez la série Maîtrise de l'outil de la Communauté Alteryx pour en savoir plus sur l'outil Union.
Exemple d'outil unique
Cet outil comporte un exemple d'outil unique. Accédez à Exemples de workflows pour savoir comment accéder à cet exemple et à de nombreux autres exemples directement dans Designer.
Composants de l'outil

L'outil Union dispose de 2 ancrages :
Ancrage d'entrée : l'ancrage d'entrée se connecte aux flux de données que vous souhaitez unifier. Les 2 crochets pointus sur l'ancrage d'entrée indiquent qu'il accepte plusieurs entrées.
Ancrage de sortie : l'ancrage de sortie affiche le jeu de données de sortie.
Comportement de l'outil Union avec AMP Engine
À partir de la version 2026.1 de Designer, lorsque les outils d'entrée sont directement connectés à l'outil Union et que l'une des entrées n'est pas valide, l'outil Union renvoie désormais des résultats partiels (données et métadonnées) de connexions d'entrée valides (correspondant au comportement d'origine du moteur), afin d'éviter l'échec du workflow lorsque certaines entrées ne sont pas valides.
Configuration de l'outil
Mode : choisir le mode de configuration. Le paramètre par défaut est Configuration automatique par nom.
Configuration automatique par nom : empiler les données par nom de colonne.
Configuration automatique par position : empiler les données par ordre de colonne dans le flux.
Configuration manuelle des colonnes : vous permet de spécifier manuellement la façon d’empiler les données. Lorsque vous choisissez cette méthode, les colonnes de chaque entrée sont affichées (indiquées par ligne n°1, n°2, etc.).
Important
Lorsque le mode est défini sur Configuration manuelle des colonnes, Alteryx suppose que la configuration ne changera pas entre la configuration de l'outil et le moment de l'exécution du workflow. S’il manque quelque chose, une erreur se produit et le workflow s’arrêtera. Pour cette raison, n’utilisez pas ce mode de configuration dans les applications analytiques et les macros.
Propriétés : configuration automatique
Lorsque les colonnes diffèrent
Pour les modes de configuration automatique, vous devez sélectionner la façon de gérer les colonnes qui diffèrent.
Dans le premier menu déroulant, choisissez votre option de traitement des erreurs…
Erreur - Arrêter le traitement des enregistrements : émettre une erreur dans la fenêtre de résultats et arrêter le traitement des enregistrements.
Avertissement - Poursuivre le traitement des enregistrements : émettre un avertissement dans la fenêtre de résultats, mais continuer le traitement des enregistrements.
Ignorer - Continuer les enregistrements de traitement : ignorer les colonnes qui diffèrent et continuer le traitement des enregistrements.
Dans le deuxième menu déroulant, choisissez votre option de sortie...
Sortir tous les champs : la sortie inclut toutes les colonnes. Des valeurs nulles remplissent les colonnes vides.
Sortir un sous-ensemble commun de champs : la sortie n'inclut que les colonnes que chaque entrée a en commun.
Propriétés : configuration manuelle des champs
Pour le mode « Configuration manuelle des champs », vous devez configurer vos colonnes de sortie dans la section Propriétés.
Pour commencer, vos flux de données sont décalés horizontalement et verticalement de sorte que les données de chaque jeu de données d'entrée sont dans des cellules différentes.
(Facultatif) Dans le menu déroulant en haut à droite, vous pouvez commencer par sélectionner soit par position ou par nom. Sélectionnez Réinitialiser pour réinitialiser les colonnes. Utilisez cette option si vous savez que vos flux de données ont des colonnes qui correspondent par position ou nom.
Ensuite, utilisez les flèches pour commencer à empiler vos données. Sélectionnez une cellule et sélectionnez la flèche gauche ou la flèche droite pour l'empiler avec le champ de données auquel elle correspond.
Sélectionnez Pas de blocage - Les méta-info ne changeront pas pour passer les lignes de données en aval sans attendre que toutes les entrées envoient des données. N'utilisez pas ce mode si la méta-information en amont change entre le moment de la configuration et celui de l'exécution.
Ordre de sortie
Sous Ordre de sortie, cochez Définir un ordre de sortie spécifique pour spécifier les données du jeu de données d'entrée qui s'affichent en premier dans le jeu de données de sortie. Une fois vérifié, sélectionnez l'un des flux de données et sélectionnez la flèche vers le haut ou vers le bas pour réorganiser.
Important
L'option Ordre de sortie peut entraîner un ralentissement des performances.
Comprendre la sortie
Deux aspects de la sortie de l'outil Union sont importants à comprendre : les noms des colonnes et l'ordre des données.
Comprendre les noms des colonnes des données de sortie
Les noms de colonnes utilisés dans le jeu de données de sortie sont extraits du flux d'entrée avec la première valeur alphabétique/numérique.
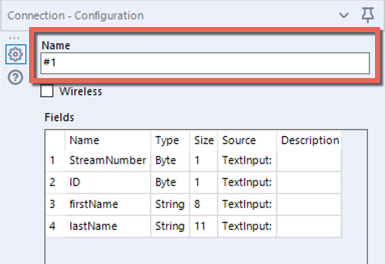
Par défaut, vos flux d'entrée de données sont étiquetés #1 et #2 en fonction de l'ordre dans lequel vous les avez connectés à l'ancrage d'entrée de l'outil Union. Ainsi, si les noms de colonnes diffèrent, le jeu de données de sortie utilise les noms de colonnes du jeu de données d'entrée #1.
Si vous préférez utiliser les noms de colonnes du jeu de données d'entrée #2, vous pouvez modifier le nom des connexions d'entrée. Pour ce faire, sélectionnez les flux d'entrée et saisissez de nouvelles valeurs dans le champ Nom des connexions. Les noms des colonnes de sortie sont issus de la connexion avec la première valeur alphabétique/numérique dans son Nom.
Comprendre l’ordre des données de sortie
L'ordre de sortie par défaut correspond souvent à l'ordre avec lequel vous avez connecté vos jeux de données d'entrée à l'ancrage d'entrée de l'outil Union, mais il peut varier. Accédez à la section Ordre de sortie pour savoir comment définir l'ordre de vos données de sortie.