Changes to the Object Model
This section identifies changes to the object model over recent releases.
For more information on the objects available in the platform, see Application Asset Overview.
Release 7.1
Introducing Plans
Beginning in Release 7.1, you can build plans, which are sequences of flow tasks (job executions). When a flow task completes, the next one is executed, and so on. Plans are a very useful means of automating job execution. For more information, see Overview of Operationalization.
See Plans Page.
Release 6.8
Version 2 of flow definition
This release introduces a new specification for the flow object.
Note
This version of the flow object now supports export and import across products and versions of those products in the future. There is no change to the capabilities and related objects of a flow.
Beginning in Release 6.8:
You can export a flow from one product and imported it into another. For example, you can develop a flow in Designer Cloud Powered by Trifacta Enterprise Edition and then import it into Designer Cloud Powered by Trifacta Educational, assuming that the product receiving the import is on the same build or a later one.
Note
Cloud-based products, such as free Designer Cloud Powered by Trifacta Educational are updated on a periodic basis, as often as once a month. These products are likely to be on a version that is later than your installed version of Designer Cloud Powered by Trifacta Enterprise Edition. For compatibility reasons, you should develop your flows in your earliest instance of Designer Cloud Powered by Trifacta Enterprise Edition on Release 6.8 or later.
You can export a flow from Release 6.8 or later of Designer Cloud Powered by Trifacta Enterprise Edition and later import into Release 7.0 after upgrading the platform.
Note
You cannot import a pre-Release 6.8 flow into a Release 6.8 or later instance of Designer Cloud Powered by Trifacta Enterprise Edition. You should re-import those flows before you upgrade to Release 6.8 or later.
Release 6.4
Macros
This release introduces macros, which are reusable sequences of parameterized steps. These sequences can be saved independently and references in other recipes in other flows. See Overview of Macros.
Release 6.0
None.
Release 5.1
None.
Release 5.0
Datasets with parameters
Beginning in Release 5.0, imported datasets can be augmented with parameters, which enables operationalizing sampling and jobs based on date ranges, wildcards, or variables applied to the input path. For more information, see Overview of Parameterization.
Release 4.2
In Release 4.2, the object model has undergone the following revisions to improve flexibility and control over the objects you create in the platform.
Wrangled datasets are removed
In Release 3.2, the object model introduced the concepts of imported datasets, recipes, and wrangled datasets. These objects represented data that you imported, steps that were applied to that data, and data that was modified by those steps.
In Release 4.2, the wrangled dataset object has been removed in place of two objects listed below. All of the functionality associated with a wrangled dataset remains, including the following actions. Next to these actions are the new object with which the action is associated.
Wrangled Dataset action | Release 4.2 object |
|---|---|
Run or schedule a job | Output object |
Preview data | Recipe object |
Reference to the dataset | Reference object |
Note
At the API level, the wrangledDataset endpoint continues to be in use. In a future release, separate endpoints will be available for recipes, outputs, and references. For more information, see API Reference.
These objects are described below.
Recipes can be reused and chained
Since recipes are no longer tied to a specific wrangled dataset, you can now reuse recipes in your flow. Create a copy with or without inputs and move it to a new flow if needed. Some cleanup may be required.
This flexibility allows you to create, for example, recipes that are applicable to all of your datasets for initial cleanup or other common wrangling tasks.
Additionally, recipes can be created from recipes, which allows you to create chains of recipes. This sequencing allows for more effective management of common steps within a flow.
Introducing References
Before Release 4.2, reference datasets existed and were represented in the user interface. However, these objects existed in the downstream flow that consumes the source. If you had adequate permissions to reference a dataset from outside of your flow, you could pull it in as a reference dataset for use.
In Release 4.2, a reference is a link between a recipe in your flow to other flows. This object allows you to expose your flow's recipe for use outside of the flow. So, from the source flow, you can control whether your recipe is available for use.
This object allows you to have finer-grained control over the availability of data in other flows. It is a dependent object of a recipe.
Note
For multi-dataset operations such as union or join, you must now explicitly create a reference from the source flow and then union or join to that object. In previous releases, you could directly join or union to any object to which you had access.
Introducing Outputs
In Release 4.1, outputs became a configurable object that was part of the wrangled dataset. For each wrangled dataset, you could define one or more publishing actions, each with its own output types, locations, and other parameters. For scheduled executions, you defined a separate set of publishing actions. These publishing actions were attached to the wrangled dataset.
In Release 4.2, an output is a defined set of scheduled or ad-hoc publishing actions. With the removal of the wrangled dataset object, outputs are now top-level objects attached to recipes. Each output is a dependent object of a recipe.
Flow View Differences
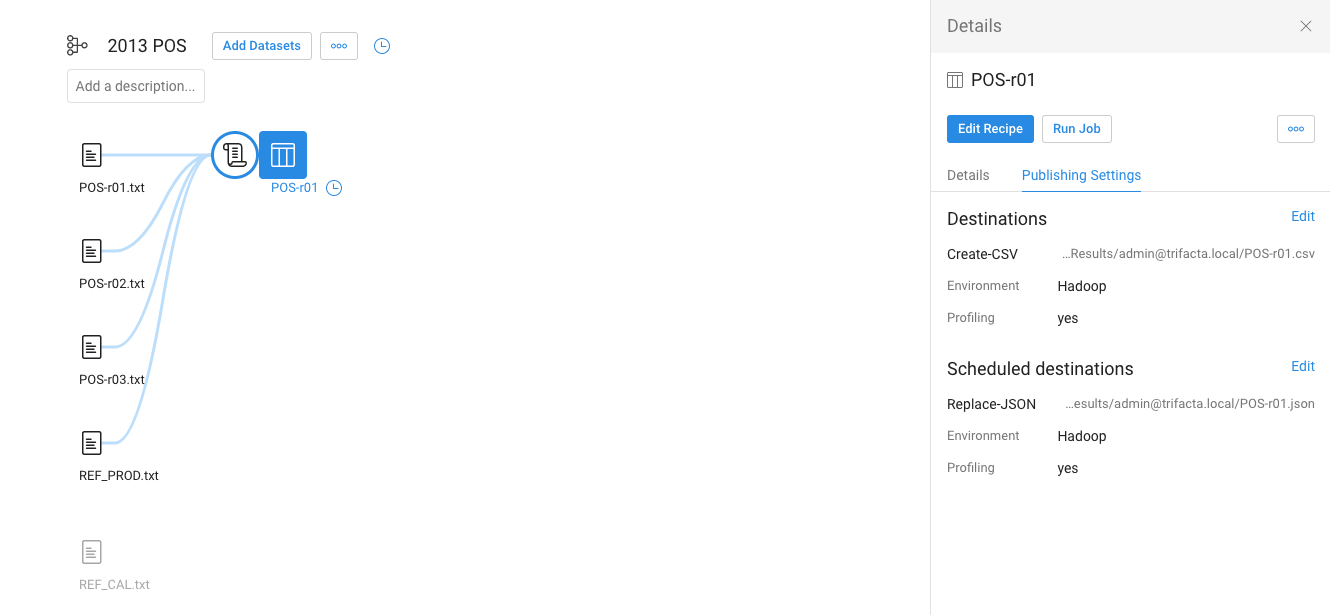
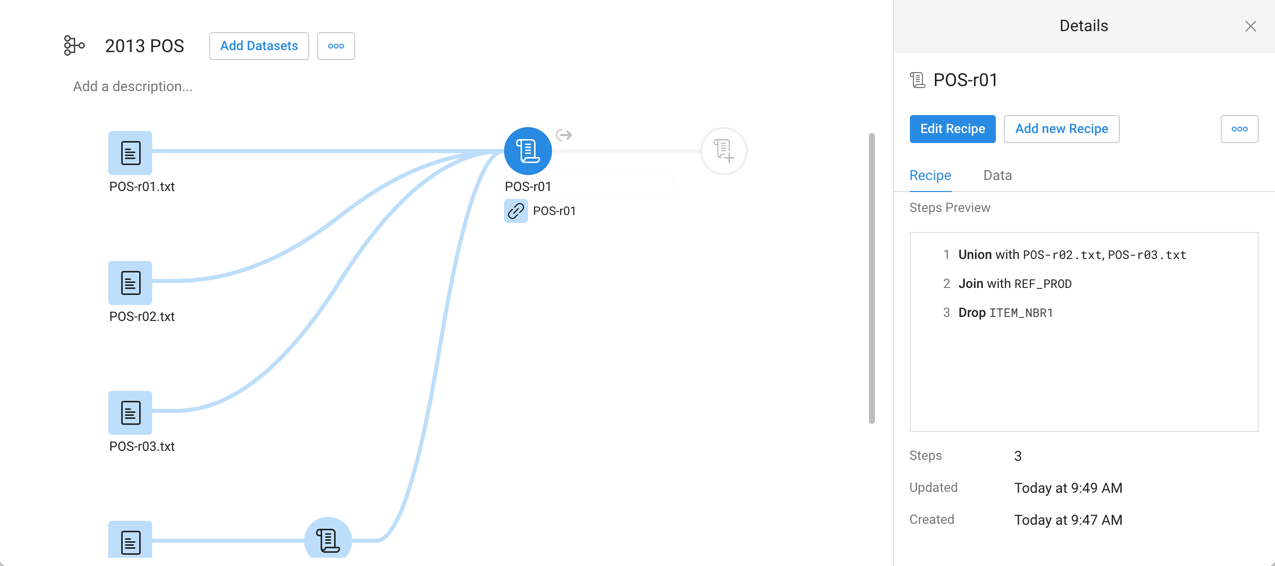
Below, you can see the same flow as it appears in Release 4.1 and Release 4.2. In each Flow View:
The same datasets have been imported.
POS-r01 has been unioned to POS-r02 and POS-r03.
POS-r01 has been joined to REF-PROD, and the column containing the duplicate join key in the result has been dropped.
In addition to the default CSV publishing action (output), a scheduled one has been created in JSON format and scheduled for weekly execution.
Release 4.1 Flow View
Release 4.2 Flow View
Flow View differences
Wrangled dataset no longer exists.
In Release 4.1, scheduling is managed off of the wrangled dataset. In Release 4.2, it is managed through the new output object.
Outputs are configured in a very similar manner, although in Release 4.2, the tab is labeled, "Destinations."
No changes to scheduling UI.
Like the output object, the reference object is an externally visible link to a recipe in Flow View. This object just enables referencing the recipe object in other flows.
See Flow View Page.
Other differences
In application pages where you can select tabs to view object types, the available selections are typically: All, Imported Dataset, Recipe, and Reference.
Wrangled datasets have been removed from the Dataset Details page, which means that the job cards for your dataset runs have been removed.
These cards are still available in the Job History page when you click the drop-down next to the job entry.
The list of jobs for a recipe is now available through the output object in Flow View. Select the object and review the job details through the right panel.
In Flow View and the Transformer page, context menu items have changed.
Connections as a first-class object
In Release 4.1.1 and earlier, connections appeared as objects to be created or explored in the Import Data page. Through the left navigation bar, you could create or edit connections to which you had permission to do so. Connections were also selections in the Run Job page.
Only administrators could create public connections.
End-users could create private connections.
In Release 4.2, the Connections Manager enables you to manage your personal connections and (if you're an administrator) global connections. Key features:
Connections can be managed like other objects.
Connections can be shared, much like flows.
When a flow with a connection is shared, its connection is automatically shared.
For more information, see Overview of Sharing.
Release 4.2 introduces a much wider range of connectivity options.
Multiple Redshift connections can be created through this interface. In prior releases, you could only create a single Redshift connection.
Note
Beginning in Release 4.2, all connections are initially created as private connections, accessible only to the user who created. Connections that are available to all users of the platform are called, public connections. You can make connections public through the Connections page.
For more information, see Connections Page.