Alteryx EngineとAMPの主な違い
Alteryx AMP Engineでは、Alteryx Engineと新しいAlteryxマルチスレッド処理(AMP)について説明しています。このページでは、両者の主な違いについて説明します。
データ処理の違い
従来のEngineのアーキテクチャでは、主にシングルスレッド処理が可能で、データはレコードごとに順次連続して処理されていました。一方、新しいAMPコンセプトでは、大規模なマルチスレッド処理が可能になります。レコードは高速化のために4 MBパケットで処理され、並列実行されるため、出力レコードの順序に影響を与える場合があります。
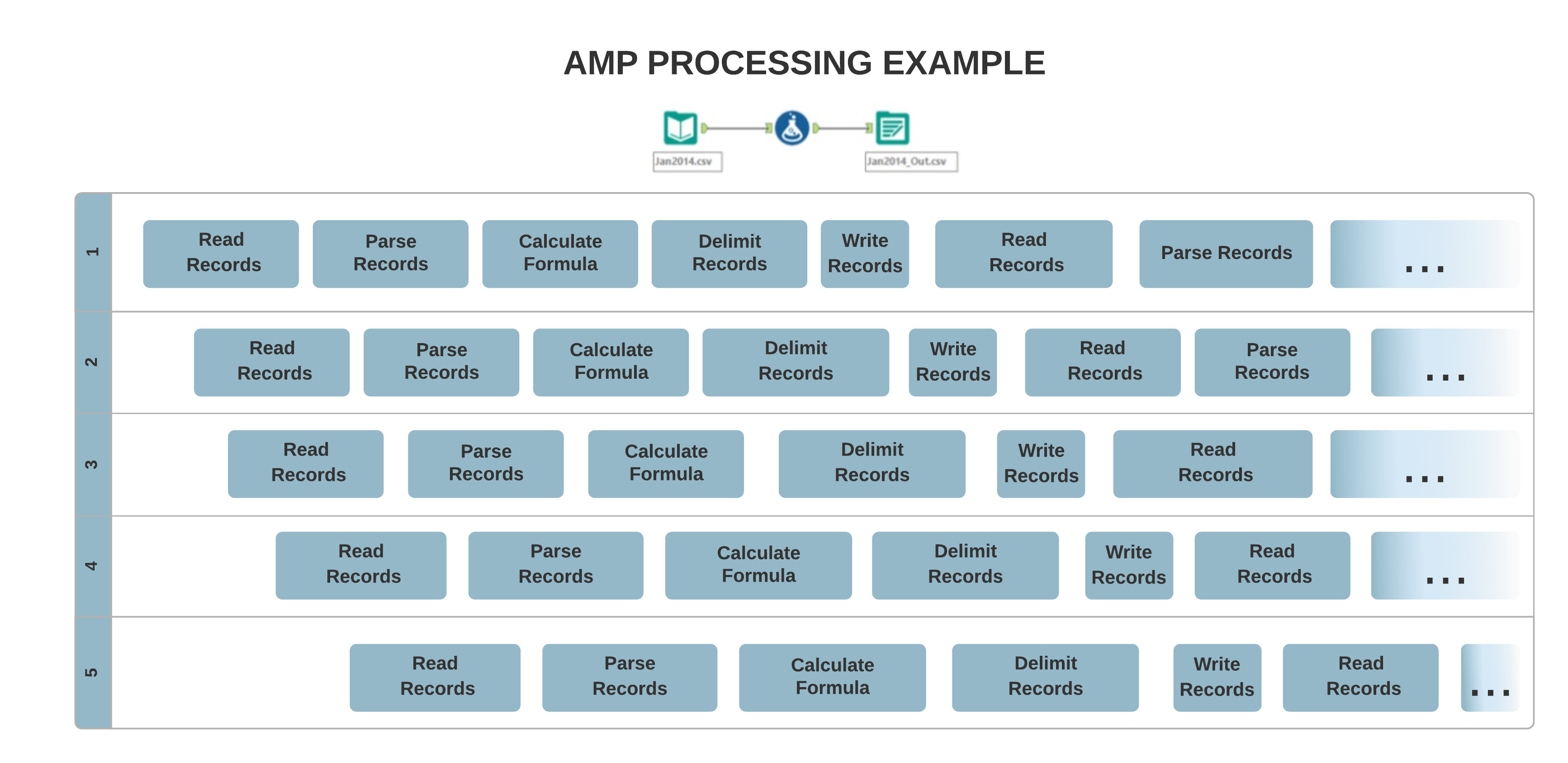
入力の違い
レコード制限
すべての入力に対するレコード制限のワークフロー設定ランタイム設定は、AMPでは次のツールで有効になります。
データ入力
テキスト入力
行生成
マクロ入力
動的入力ツールにおけるツールレベルのレコード制限に対するAMPサポートは、2021.1パッチ2以降のすべてのリリースで追加されました。
出力の違い
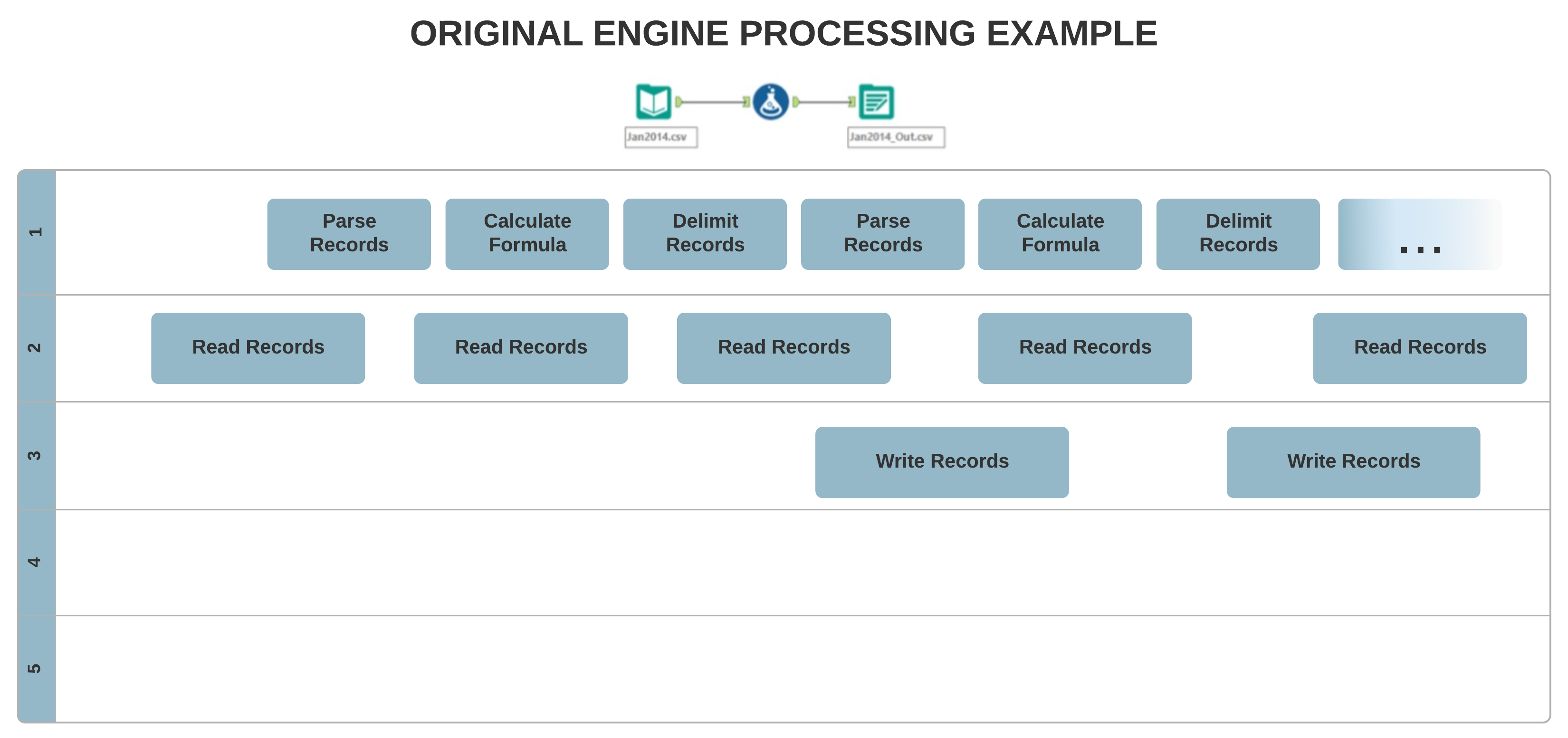
ワークフローをAMP Engineで実行すると、いくつかのツールは従来のEngineと異なる順序でレコードを出力することがあります。それには、次のようなツールが含まれます。
クロスタブ
データクレンジング (NULL 行を削除する場合)
結合
複数結合
複数行フォーミュラ
ポリビルド
累計
ソート (辞書ソートが特殊文字に対し使用されている場合)
集計 (グループ化が使用されている場合)
タイル
ユニオン
ユニーク
ワークフローで、上記のツールのレコードを下流のツールの作業のために特定の順序にする必要がある場合は、エンジン互換モード設定を使用して、従来のEngineと同じ並べ替え順序を維持できます。これは、主に従来のEngineで作成されたワークフローをAMP Engineで実行するために移行する場合など、特定のワークフローを慎重に検討した上で使用してくださいす。
AMPに変換されていない特定の機能または設定は、従来のEngineバージョンのツールに戻って動作します。したがって、AMP変換ツールと変換ツール以外の両方のツールを含むワークフローは、AMPとシームレスに実行されます。
AMPに変換されたツールについて不明な点がある場合は、AMPでのツール使用を参照してください。
従来のEngineではツールのつながりが強く、下流に何もなければすぐに機能が停止します。AMP並列実行では、下流に何もなくてもツールが停止しない場合があります。下流に何もない場合、データストリームは処理されないというのが前提です。ログメッセージは、単なる情報の通知です。ストリーム内のレコード数が重要な場合は、テストツールを使用して、適切なレコード数が得られない場合にエラーメッセージを生成させることができます。
パフォーマンスの読み取り
AMP Engine で書き込まれた YXDB ファイルは、従来の Engine で書き込まれた YXDB よりも高速に読み込まれます。従来のEngineで書き込まれたYXDBファイルは、AMPが有効になっていると、読み取り速度が遅くなります。ただ、これらの形式に互換性があることに変わりはありません。
AMP では、XLSX、CSV、YXDB、および SQLite ファイル形式を使用し、これらのファイル形式は、マルチスレッドの読み込みデータをサポートしています。
Zipファイルを読み込むときに、従来のEngineとAMPの間でレコードを変換してパッケージ化すると、パフォーマンスが低下します。これにより、AMPでは大きなZipファイルの読み取り速度が大幅に低下する可能性があります。
ヒント
テキストエディターで開くと、AMP で記述された YXDB ファイルには、ファイル内容の最初に「Alteryx e2 Database file」があります。従来のEngineで書き込まれたファイルは、同じ場所に「Alteryxデータベースファイル」と記載されます。
書き込みパフォーマンス
従来のEngineのパフォーマンスを向上させる(従来のEngineで作成されたYXDBファイルをAMPで書き込む)には、[データ出力] - [設定]メニューに、Designerバージョン18.1以前のバージョンと互換性のあるYXDBファイルを作成するオプションがあります。
出力ツールは、従来のEngineとAMP EngineでCSVファイルを保存するとき、SpatialObjデータを含むレコードでの挙動が異なります。AMPはCSVファイルとして保存するときにSpatialObjデータをファイルに書き込みますが、従来のEngineは書き込みません。この違いによりファイルサイズに違いが生じ、パフォーマンスが低下する可能性があります。
必要な場合は回避策として、セレクトツールを介してレコードからこの空間データを削除することができます。これにより、両方のエンジンが同様の時間で完了します。
パフォーマンスプロファイル
AMPを使用したツールごとのパフォーマンスプロファイリングは、Designerのバージョン2021.3以降で利用できます。
Rツールのパフォーマンス
データは、AMP と R との間では従来の Engine の形式で渡されます。二重変換には時間がかかります。単一Rツールの実行時間は、従来のEngineよりもAMPの方が遅くなる可能性がありますが、複数のブランチが同時に実行される場合はより速くなります。
テキスト入力ツールとオートフィールドツール
AMP は、下流のツールで処理したときにフィールドのサイズが不足するという問題に対処しました。結果のデータが元のデータ型の長さを超える場合に、データ型を変更するセレクトツールを追加する必要はありません。AMPは文字列と整数に最大サイズフィールドを作成し、以降の操作では、より大きな下流の値に対応するために十分な容量を保ちます。
テキスト入力ツールを使用する際、AMPでは従来のEngineよりも信頼性が高く明示的なデータ型を利用できます。
従来のEngine:「F」や「T」などの特定の文字値をブール値のFalseとTrueに自動的に変換します。これにより、単一文字の文字列を入力した場合に、予期せず型が変換される可能性があります。
AMP:「F」または「T」をブール値に自動変換しません。これらの値は、ブール値として明確に定義されていない限り、文字列として保持されます。これにより、予期しない型に変換されるのを防ぎ、より予測可能な動作で利用できます。
スロットルツール
スロットルツールは完全にはAMP用に変換されていませんが、ダウンロードツールと一緒に使用できます(スロットルツールを先に使用してください)。
ファジーマッチ
ファジーマッチは、従来のEngineとAMPでは異なる結果を出力する場合があります。AMPレコードは、別の方法を使用して照合されます。一致の順序が異なる場合があり、出力も順序が逆になる場合があります。ファジーマッチは、従来のEngineに比べてAMPでのパフォーマンスが低いという既知の問題があります。
正規表現ツール
AMPではUnicodeおよびPerlのエンコード標準が使用され、文字$、+、<、=、>、^、|、および~は句読点として認識されません。式関数REGEX_Replaceまたは正規表現ツールを使用して、正規表現セット[[:punct:]]で句読点をフィルタリングする際に、AMPを使用する場合は式を変更する必要があります。
例
REGEX_REPLACE([_CurrentField_],'[[:punct:]]|[\$\+<=>\^`\|~]','')
グループ化ツールとブロックツール
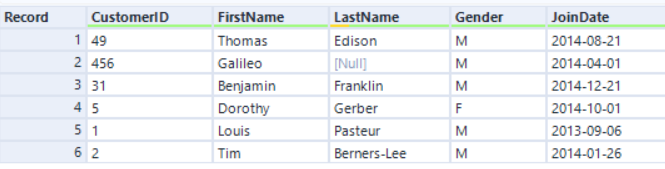
従来のEngineを使用する結合アルゴリズムは、ソートマージ結合方式に基づいており、レコードは常に並び替えられた順序で実行されます。AMPを使用した新しい結合アルゴリズムはハッシュ結合方式に基づいているため、レコードは順序通りに出力されません。例:

左入力:
右入力:
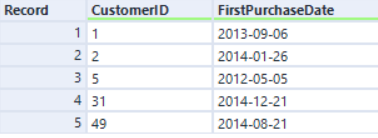
従来のEngineとCustomerIDで結合する場合、レコードの順序は以下のようにCustomerIDフィールドで並べ替えられます。

AMPでは、レコードは同じですが、順序は異なります。

結合出力の並べ替え順序を設定する必要がある場合は、結合ツールの後にソートツールを追加するか、[ワークフロー設定] > [ランタイム]で[AMP Engineを使用する]設定の下の[エンジン互換モード]設定を有効にします。
反復マクロ
従来のEngineとAMPの違いは、マクロ内のツールがエラーを報告した際に表れます。シングルスレッドの場合、マクロでエラーが発生すると、従来のEngineは停止します。AMPは、反復出力が空になるまで、または最大反復回数に達するまで機能します。実行される反復回数が多いため、次のような状況が発生する可能性があります。
AMPではエラーが発生した場合に、エラー数が従来のEngineより多くなることがある。
AMPではレコード数が従来の Engine より多くなることがある。
出力スキーマが AMP 実行時には異なることがある。
フォーミュラツール
フォーミュラツールのConvertFromCodePageおよびConvertToCodePage関数は、文字列をパラメーターとして受け取り、結果として文字列を返します。そのため、文字列がどのようにエンコードされているかは識別できません。これらの関数を従来のEngineとAMPで使用した場合、フォーミュラツールの出力が異なります。
AMP内部ではUTF-8でエンコードされた文字列を使用するため、入力データのバイナリ表現が異なります。異なるエンコードのデータをインポートした場合、元のデータに戻す方法はありません。従来のEngineでは、バッファとして使用された文字列をLatin-1またはUTF-16でエンコードして保存しているため、データを正しく元通りに変換できます。
フォーミュラアドイン
フォーミュラアドインは、AMPでは現在サポートされていません。フォーミュラアドイン機能を含むワークフローを実行する必要がある場合は、従来の Engineを使用して実行してください。
重要
フォーミュラアドインは、2023.2リリース以降でAMPを介してサポートされています。
分析アプリ
マップツールを使用して、分析アプリの空間参照レイヤーから選択するアプリは、引き続き、従来のEngineを使用する必要があります。
等しいことを検証
従来のEngineでは、等しいことを検証ツールはCReWマクロのままです。AMPでは、ネイティブツールとして実行されます。
並列分岐実行とツールの実行順序
一部のワークフローは、ファイルから読み取った後、書き戻しを行います。これには、書き込みを開始する前に読み取りが完了したことを確認するために、シーケンスが必要です。同様に、1つのXLSXファイルに複数のシートを書き込むワークフローでは、シートを1つずつ書き込む必要があります。Designerには、完了までブロックツールが用意されており、処理をフェーズに分けて、処理をお互いに干渉しないようにすることができます。
Eメールツールについても、前のブランチからの出力ファイルを添付ファイルとして使用する場合、同じ回避策が適用されます。データ処理が完了するまで待ち、その後にEメールツールに添付ファイルとして追加してください。
複数のブランチ(主に入力から出力に大別されるストリーム)を持つワークフローで作業する場合、入力ツールIDの番号が最も小さいワークフローのブランチに、完了までブロックツールを配置します。これにより、後続のすべてのブランチが前のブランチが完了するまで実行を待機し、ツールが期待通り動作するよう保証します。
利用可能な機能
特定のツール機能の詳細については、AMPでのツール使用を参照してください。