Parameterize Files for Import
This section describes how to create datasets and replace segments by parameterizing the input paths to your data in the Alteryx One .
Structuring Your Data
Each file that is included as part of the dataset with parameters should have identical structures:
Matching file formats
Matching column order, naming, and data type
Matching column headers. Each column in any row that is part of a column header in a dataset with parameters should have a valid value that is consistent with corresponding values across all files in the dataset.
Anmerkung
If your files have missing or empty values in rows that are used as headers, these rows may be treated as data rows during the import process, which may result in unexpected or missing column values.
Within each column, the data format should be consistent.
For example, if the date formats change between files in the source system, you may not be able to manage the differences, and it is possible that data in the output may be missing.
Anmerkung
Avoid creating datasets with parameters where individual files or tables have differing schemas. Either import these sources separately and then correct in the application before performing a union on the datasets, or make corrections in the source application to standardize the schemas.
When working with datasets with parameters, it may be useful to do the following if you expect the underlying datasets to be less than 100% consistent with each other.
Recreate the dataset with parameters, except deselect the Detect Structure option during the import step.
If possible, collect a Random Sample using a full scan. This step attempts to gather data from multiple individual files, which may illuminate problems across the data.
Tipp
If you suspect that there is a problem with a specific file or rows of data (e.g. from a specific date), you can create a static dataset from the file in question.
Steps
Anmerkung
Matching file path patterns in a large directory can be slow. Where possible, avoid using multiple patterns to match a file pattern or scanning directories with a large number of files. To increase matching speed, avoid wildcards in top-level directories and be as specific as possible with your wildcards and patterns.
In the Data page, navigate your environment to locate one of the files or tables that you wish to parameterize.
Select three dot menu and select Create Dataset with Parameters.
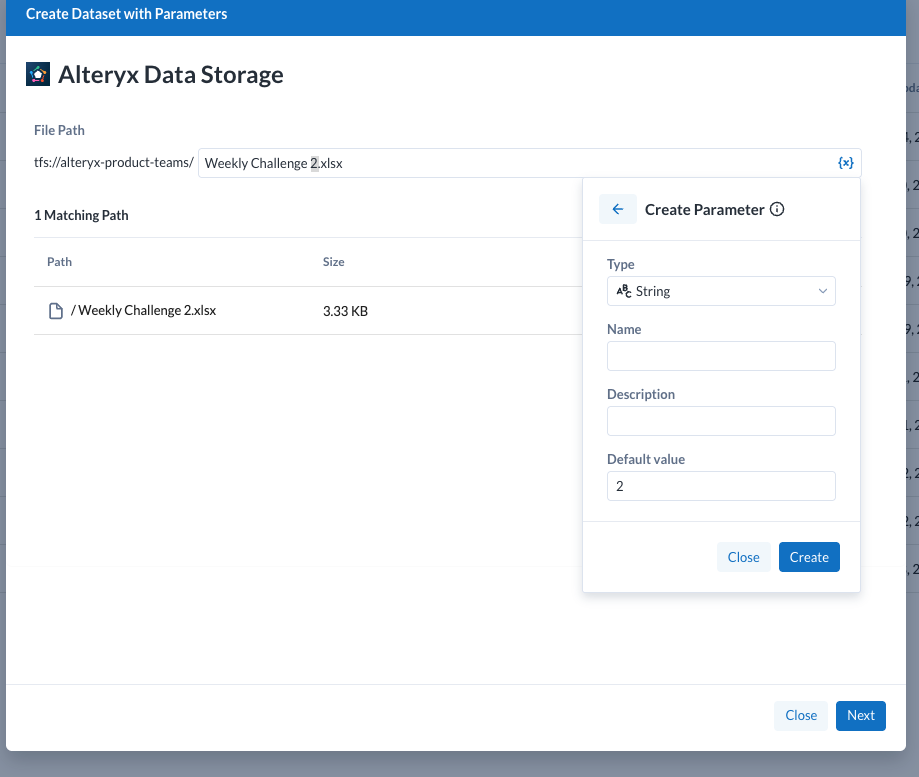
Within the Define Parameterized Path, select a segment of text. Then select one of the following options:
Tipp
For best results when parameterizing directories in your file path, include the trailing slash (
/) as part of your parameterized value.Add Variable
Add Pattern Parameter - wildcards and patterns
If you need to navigate elsewhere, select Browse.
Specify the parameter. Click Save.
Click Update matches. Verify that all of your preferred datasets are matching.
Anmerkung
If you are matching with more datasets than you wish, you should review your parameters.
Click Create.
The parameterized dataset is loaded.
Add Variable
A variable parameter is a key-value pair that can be inserted into the path.
At execution time, the default value is applied, or you can choose to override the value.
A variable can have an empty default value.
Name: The name of the variable is used to identify its purpose.
Anmerkung
If multiple datasets share the same variable name, they are treated as the same variable.
Tipp
Type env. to see the environment parameters that can be applied. These parameters are available for use by each user in the environment.
Default Value: If the variable value is not overridden at execution time, this value is inserted in the variable location in the path.
Anmerkung
When you edit an imported dataset, if a variable is renamed, a new variable is created using the new name. Any override values assigned under the old variable name for the dataset must be re-applied. Instances of the variable and override values used in other imported datasets remain unchanged.
Add Pattern Parameter
In the screen above, you can see an example of pattern-based parameterization. In this case, you are trying to parameterize the two digits after the value: POS-r.
Include nested folders
Anmerkung
You cannot create multiple wildcard parameters when the Include nested folders option is selected. When this option is selected for the dataset, only one wildcard parameter is supported.
When you create a wildcard or pattern-based parameter, you have the option to scan any nested folders for matching sources.
If disabled, the scan stops when the next slash (
/) in the path is encountered. Folders are not matched.If enabled, the scan continues to any depth of folders.
Anmerkung
A high number of files and folders to scan can significantly increase the time required to load your dataset with parameters.
Example 1: all text files
Suppose your file and folder structure look like the following:
//source/user/me/datasets/thisfile.txt //source/user/me/datasets/thatfile.txt //source/user/me/datasets/anotherfile.csv //source/user/me/datasets/detail/anestedfile.txt //source/user/me/datasets/detail/anestedfile2.txt //source/user/me/datasets/detail/anestedfile4.txt //source/user/me/ahigherfile.txt
Since the filenames vary significantly, it may be easiest to create your pattern based on a wildcard. You create a wildcard parameter on the first file in the //source/user/me/datasets directory:
//source/user/me/datasets/*.txt
For the specified directory, the above pattern matches on any text file (.txt). In the example, it matches on the first two files but does not match on the CSV file.
When the Include nested folders checkbox is selected:
The first two files are matched.
The next three files inside a nested folder are matched.
The last file (
ahgherfile.txt) is not matched, since it is not inside a nested folder.
Example 2: pattern-based files
Suppose your file and folder structure look like the following:
//source/user/me/datasets/file01.csv //source/user/me/datasets/file02.csv //source/user/me/datasets/file03.csv //source/user/me/datasets/detail/file04.csv //source/user/me/datasets/detail/file05.csv //source/user/me/datasets/detail/file06.csv //source/user/me/file07.csv
You create a pattern parameter on the first file in the //source/user/me/datasets directory with the following pattern-based parameter:
`file{digit}+` The above pattern matches on the word file and a sequence of one or more digits. For example, suppose file100.csv lands in the directory at some point in the future. This pattern would capture it.
In the above example, this pattern matches on the first three files, which are all in the same directory.
When the Include nested folders checkbox is selected:
The first three files are matched.
The next three files inside a nested folder are matched.
The last file (
file07.csv) is not matched, since it is not inside a nested folder.
Wildcard
The easiest way to is to add a wildcard: *
A wildcard can be any value of any length, including an empty string.
Tipp
Wildcard matching is very broad. If you are using wildcards, you should constrain them to a very small part of the overall path. Some running environment may place limits on the number of files with which you can match.
Pattern - Regular expression
Instead of a wildcard match, you could specify a regular expression match. Regular expressions are a standardized means of expressing patterns.
Regular expressions are specified between forward slashes, as in the following:
/my_regular_expression/
Anmerkung
If regular expressions are poorly specified, they can create unexpected matches and results. Use them with care.
The following regular expression matches the same two sources in the previous screen:
/\_[0-9]*\_[0-9]*/
The above expression matches an underscore (_) followed by any number of digits, another underscore, and any number of digits.
Tipp
In regular expressions, some characters have special meaning. To ensure that you are referencing the literal character, you can insert a backslash (\) before the character in question.
While the above matches the two sources, it also matches any of the following:
_2_1 __1 _1231231231231231235245234343_
These may not be proper matches. Instead, you can add some specificity to the expression to generate a better match:
/\_[0-9]{13}\_[0-9]{4}/The above pattern matches an underscore, followed by exactly 13 digits, another underscore, and then another 4 digits. This pattern matches the above two sources exactly, without introducing the possibility of matching other numeric patterns.
Pattern - Alteryx pattern match
A Alteryx pattern is a platform-specific mechanism for specifying patterns, which is much simpler to use than regular expressions. These simple patterns can cover much of the same range of pattern expression as regular expressions without the same risks of expression and sometimes ugly syntax.
Alteryx patterns are specified between back-ticks, as in the following:
`my_pattern`
In the previous example, the following regular expression was used to match the proper set of files:
/\_[0-9]{13}\_[0-9]{4}/In a Alteryx pattern, the above can be expressed in a simpler format:
`\_{digit}{13}\_{digit}{4}`This simpler syntax is easier to parse and performs the same match as the regular expression version.