Dans l'article Alteryx AMP Engine nous avons abordé ce qu'est Alteryx Engine et le nouveau Alteryx Multi-Threaded Processing(AMP). Dans cette partie, nous allons voir plus en détail les principales différences entre les deux.
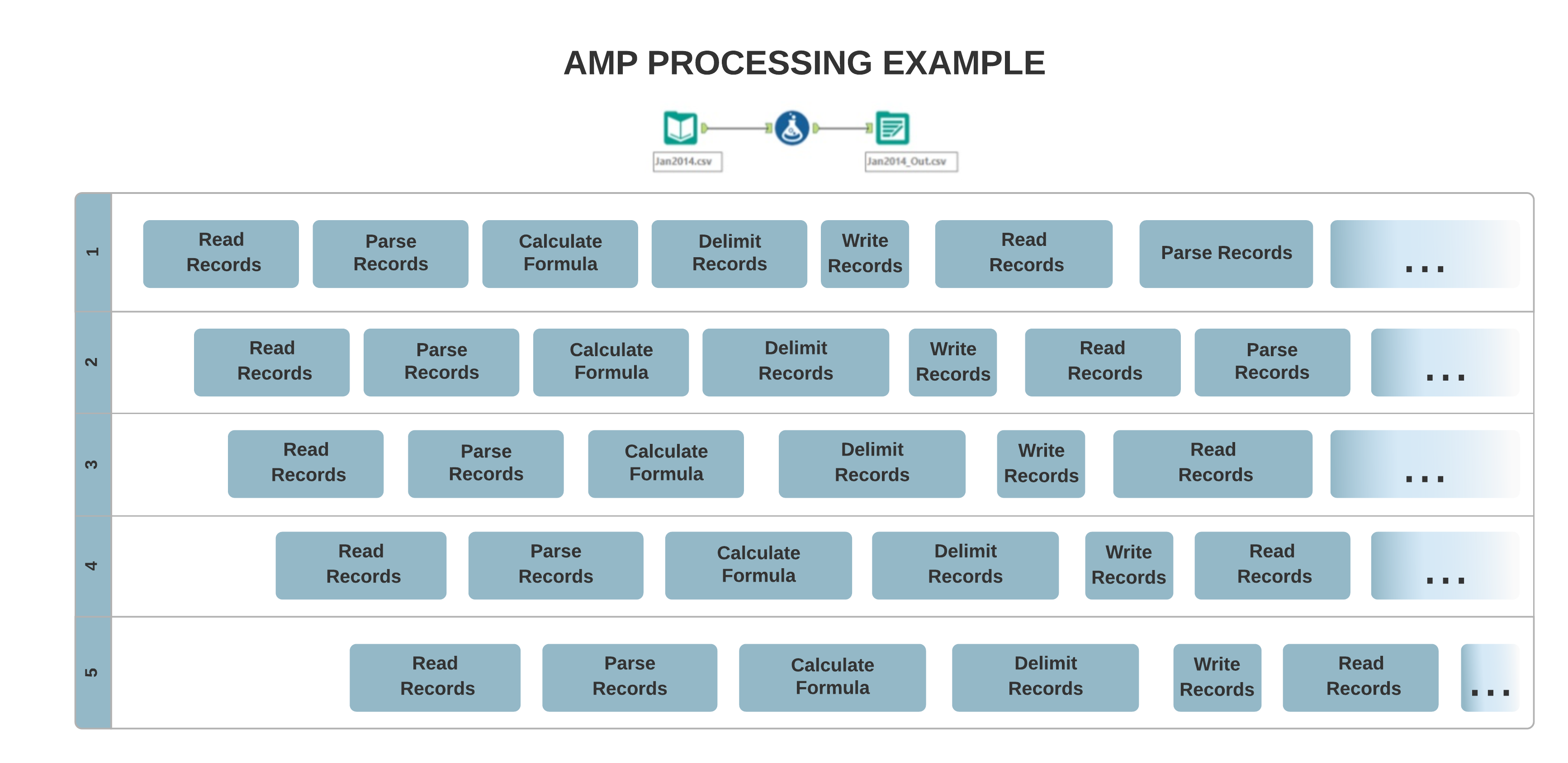
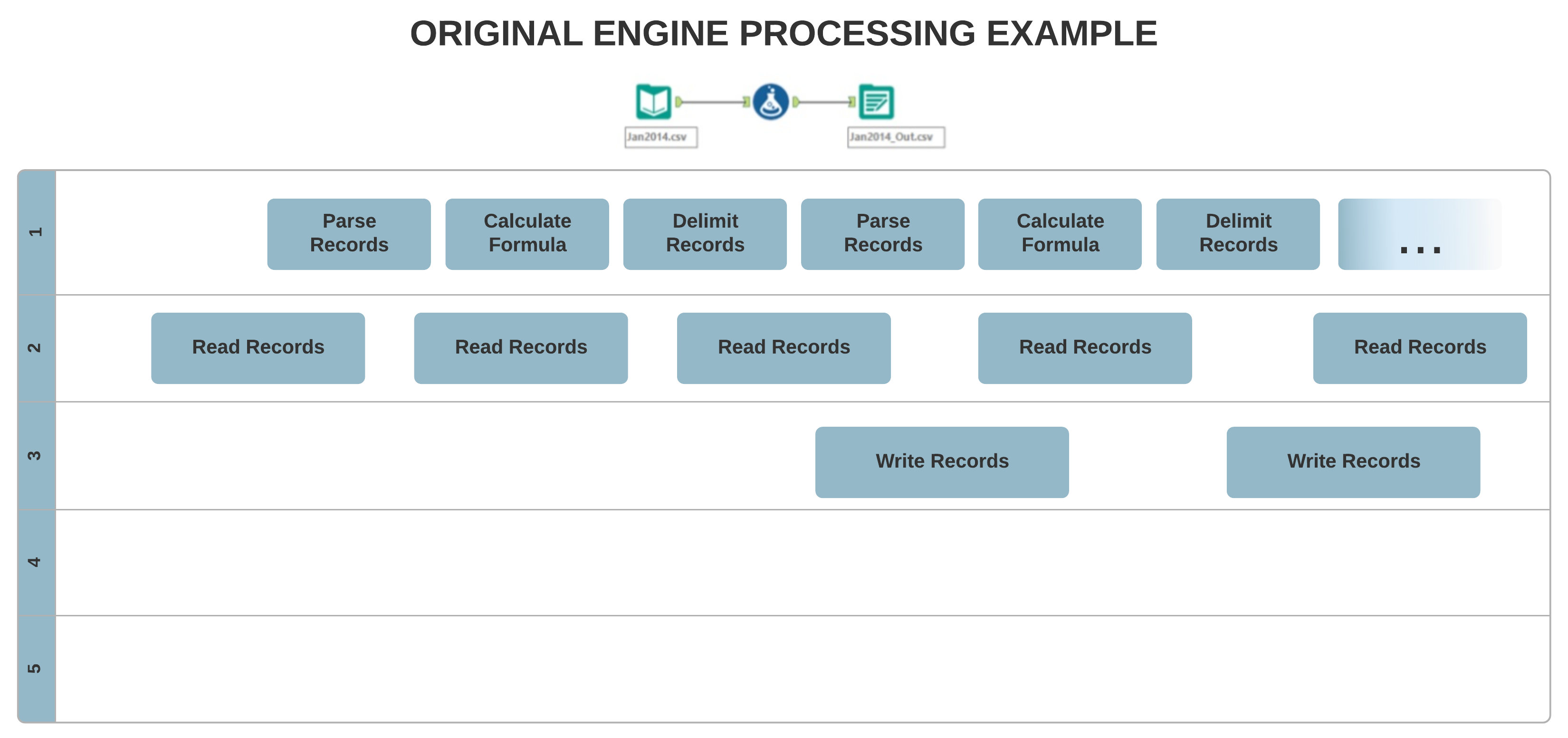
L'architecture du moteur d'origine permet un traitement à thread unique, où vos données sont traitées de façon séquentielle, enregistrement par enregistrement. En revanche, le nouveau concept AMP permet un traitement multi-threaded massif. Les enregistrements sont traités dans des paquets de 4 Mo, pour un temps d'exécution plus rapide et parallèle, ce qui peut affecter l'ordre des enregistrements de sortie.
Les fichiers CSV contenant un champ avec de nouvelles lignes entre guillemets échoueront si vous n'activez pas l'option supplémentaire AMP uniquement : les champs entre guillemets peuvent contenir de nouvelles lignes.
Le paramètre d'exécution de la configuration du workflow Limite d'enregistrements pour toutes les entrées est activé avec AMP pour les outils suivants :
Entrée de données
Saisie de texte
Générer les lignes
Entrée de macro
La prise en charge d'AMP pour la limite d'enregistrements au niveau de l'outil dans l'outil Entrée dynamique a été ajoutée dans le correctif 2 de la version 2021.1 et dans toutes les versions ultérieures.
Lorsqu'un workflow est exécuté avec AMP Engine, plusieurs outils peuvent générer des enregistrements dans un ordre différent de celui du moteur d'origine. Certains de ces outils incluent...
Tableau croisé dynamique
Nettoyage des données (lors de la suppression de lignes nulles)
Jointure
Plusieurs Jointures
Formule à plusieurs lignes
PolyBuild
Total cumulé
Trier (lorsque le tri du dictionnaire est utilisé avec des caractères spéciaux)
Agréger (lorsque l'option Regrouper par est utilisée)
Ensemble
Union
Unique
Si votre workflow nécessite que les enregistrements des outils ci-dessus soient triés dans un ordre spécifique pour les opérations en aval, le paramètre Mode de compatibilité du moteur est disponible pour maintenir le même ordre de tri que celui du moteur d'origine. Utilisez ce paramètre après avoir soigneusement pris en compte le workflow spécifique, principalement lors de la migration de workflows créés avec le moteur d'origine pour une exécution avec AMP Engine.
Des fonctionnalités ou des paramètres spécifiques qui n'ont pas été convertis pour être utilisés avec AMP reviennent au moteur d'origine pour fonctionner. Par conséquent, les workflows qui contiennent à la fois des outils convertis et non convertis pour utiliser AMP sont parfaitement exécutables avec AMP.
Si vous avez des questions sur les outils qui ont été convertis pour utiliser AMP, consultez la rubrique Utilisation d'outils avec AMP.
Avec le moteur d'origine, les outils sont davantage connectés et cessent de fonctionner dès qu'ils ne détectent rien dans le flux en aval. Avec l'exécution parallèle d'AMP, les outils peuvent continuer de fonctionner même quand le flux en aval est vide. Il est présumé qu'avec l'aval vide, le flux de données n'est pas pris en compte. Le message de journal est fourni uniquement à titre indicatif. Si le nombre d'enregistrements dans le flux est important pour vous, vous pouvez y placer un outil Test et lui faire envoyer un message d'erreur s'il n'obtient pas le bon nombre d'enregistrements.
Un fichier YXDB écrit avec l'AMP Engine est lu plus rapidement qu'un fichier YXDB écrit avec le moteur d'origine. Un fichier YXDB écrit avec le moteur d'origine est lu plus lentement avec AMP activé. Cependant, les formats demeurent compatibles.
Utilisez les formats de fichiers XLSX, CSV, YXDB et SQLite avec AMP : ils prennent en charge les données de lecture multi-thread.
La conversion des enregistrements et du packaging entre le moteur d'origine et AMP lors de la lecture de fichiers Zip ralentit les performances. Cela peut ralentir considérablement la lecture des fichiers Zip plus volumineux avec AMP.
Conseil
Lorsqu'il est ouvert dans un éditeur de texte, un fichier YXDB écrit avec AMP affiche « Alteryx e2 Database file » au tout début du contenu du fichier. En revanche, un fichier écrit avec le moteur d'origine affiche « Alteryx Database File » au même endroit.
Pour améliorer les performances du moteur d'origine (en faisant écrire à AMP un fichier YXDB créé avec le moteur d'origine), accédez au menu Configuration de l'outil Sortie de données, où vous pouvez créer une version du fichier YXDB compatible avec Designer 18.1 et versions antérieures.
L'outil Sortie se comporte différemment avec les enregistrements qui contiennent des données SpatialObj lorsque vous enregistrez un fichier CSV avec le moteur d'origine et l'AMP Engine. Alors qu'AMP écrit les données SpatialObj dans le fichier lorsqu'il l'enregistre sous forme de fichier CSV, le moteur d'origine ne le fait pas. Cette différence entraîne des variations de taille de fichier et vous pouvez constater une baisse des performances.
Si nécessaire, une solution de contournement consiste à supprimer les données spatiales des enregistrements via l'outil Sélectionner. Cela permet aux deux moteurs de terminer leur tâche dans un délai similaire.
Le profilage des performances par outil avec AMP est disponible dans Designer version 2021.3 et dans les versions ultérieures.
AMP transmet les données vers et depuis R au format du moteur d'origine. Cette double conversion prend du temps. Le temps d'exécution d'un seul outil R peut être plus lent avec l'AMP qu'avec le moteur d'origine, mais il est plus rapide si plusieurs branches sont exécutées simultanément.
AMP traite un problème historique où la taille du champ peut ne pas être assez grande lorsqu'il est traité par un outil en aval. Vous n'avez pas besoin d'ajouter des outils Sélectionner pour modifier les types de données lorsque les données résultantes dépassent la longueur du type de données d'origine. AMP crée un champ de taille maximale pour les chaînes et les nombres entiers afin que les opérations ultérieures aient la marge de manœuvre nécessaire pour contenir des valeurs en aval plus grandes.
Bien que l’outil Régulateur n’ait pas été entièrement converti en AMP, vous pouvez l’utiliser avec l’outil Télécharger (Utilisez l'outil Régulateur en premier).
L'outil Correspondance partielle peut générer des résultats différents entre le moteur d'origine et AMP. Les enregistrements AMP sont appariés à l’aide d’une méthode alternative. L'ordre de correspondance peut être différent et la sortie peut être aussi dans l'ordre inverse. Il existe un problème de performances connu avec l'outil Correspondance partielle étant moins performant avec AMP que le moteur d'origine.
AMP utilise les normes de codage Unicode et Perl, où les caractères $, +, <, =, >, ^, | et ~ ne sont pas considérés comme de la ponctuation. Lorsque vous utilisez la fonction de la formule REGEX_Replace ou l'outil RegEx pour filtrer la ponctuation à l'aide de l'ensemble RegEx [[:punct:]], vous devez changer l'expression avec AMP.
REGEX_REPLACE([_CurrentField_],'[[:punct:]]|[\$\+<=>\^`\|~]','')
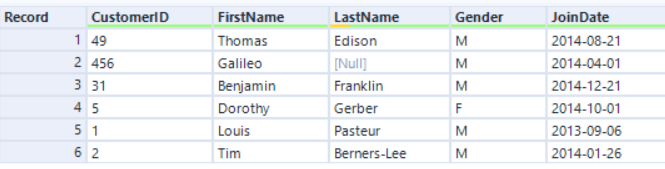
Dans le moteur d'origine, l'algorithme de l'outil Jointure est basé sur la méthode de jointure par tri-fusion, où les enregistrements apparaissent toujours dans un ordre trié. Dans AMP, le nouvel algorithme de l'outil Jointure est basé sur une méthode de jointure par hachage, de sorte que les enregistrements apparaissent de manière désordonnée. Par exemple…

Entrée gauche :
Entrée droite :
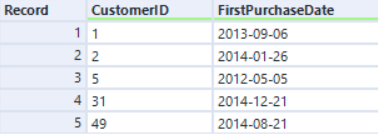
Si nous effectuons la jointure par la colonne CustomerID en utilisant le moteur d'origine, l'ordre des enregistrements est trié par le champ CustomerID :

En utilisant AMP, les enregistrements sont les mêmes, mais dans un ordre différent :

Si vous avez besoin d'avoir une sortie ordonnée, ajoutez l'outil Trier après l'outil Jointure ou activez le paramètre Mode de compatibilité du moteur dans Configuration du workflow > Exécution, sous le paramètre Utiliser l'AMP Engine.
La différence entre le moteur d’origine et AMP peut se produire lorsqu’un outil à l’intérieur de la macro signale une erreur. En étant un thread unique, le moteur d’origine s’arrête si une erreur se produit dans la macro. AMP fonctionne jusqu'à ce que la sortie itérative soit vide ou que le nombre maximum d'itérations se produise. Vous pouvez rencontrer ces situations, en raison d'un plus grand nombre d'itérations :
Le nombre d’erreurs (le cas échéant) peut être plus élevé avec AMP.
Le nombre d'enregistrements peut être plus élevé avec AMP.
Le schéma de sortie peut être différent avec AMP.
Les fonctions ConvertFromCodePage et ConvertToCodePage de l'outil Formule acceptent la chaîne comme paramètre et renvoient la chaîne comme résultat. Il n'est donc pas possible de distinguer la façon dont la chaîne est codée. Il existe une différence dans la sortie de l'outil Formule lorsque ces fonctions sont utilisées avec le moteur d'origine et AMP.
Une représentation binaire différente des données entrantes est causée par l'utilisation interne par AMP de chaînes codées UTF-8. Lorsque les données avec un codage différent sont importées, il est impossible de restaurer les données d'origine. Le moteur d'origine stocke les chaînes sous forme de chaînes codées Latin-1 ou UTF-16 qui ont été utilisées comme tampon et permettent de reconvertir les données correctement.
Les compléments de formules ne sont pas encore compatibles avec AMP. Si vous avez besoin d'exécuter un workflow contenant la fonctionnalité Compléments de formules, exécutez-le sur le moteur d'origine.
Les applications utilisant l'outil Carte pour sélectionner à partir d'une couche de référence spatiale dans une application analytique doivent continuer à utiliser le moteur d'origine.
Avec le moteur d'origine, l'outil Attendre des flux égaux reste une macro CReW. Avec AMP, il fonctionne comme un outil natif.
Certains workflows lisent un fichier, puis réécrivent dans le même fichier. Cela nécessite une séquence qui assure que la lecture est terminée avant que l'écriture ne commence. De même, un workflow qui vise à écrire plusieurs feuilles dans un fichier XLSX doit écrire une feuille à la fois. Alteryx Designer fournit l'outil Bloquer jusqu'à la fin pour aider à diviser le travail en phases qui ne sont pas l’une sur le chemin de l’autre.
La même solution s'applique à l'outil E-mail lorsque vous utilisez le ou les fichiers de sortie des branches précédentes comme pièces jointes. Vous devez attendre que le traitement des données soit terminé, puis les ajouter en pièces jointes à l'outil E-mail.
Lorsque vous travaillez sur un workflow avec plusieurs branches (flux largement séparés des entrées vers les sorties), placez l'outil Bloquer jusqu'à la fin dans la branche du workflow qui possède l'outil d'entrée avec l'identifiant le plus bas. Cela fait que chaque branche subséquente n’est exécutée que lorsque la branche précédente soit terminée, ce qui garantit que les outils fonctionnent comme prévu.
Pour plus d'informations sur le fonctionnement spécifique de chaque outil, voir : Utilisation d'outils avec AMP.